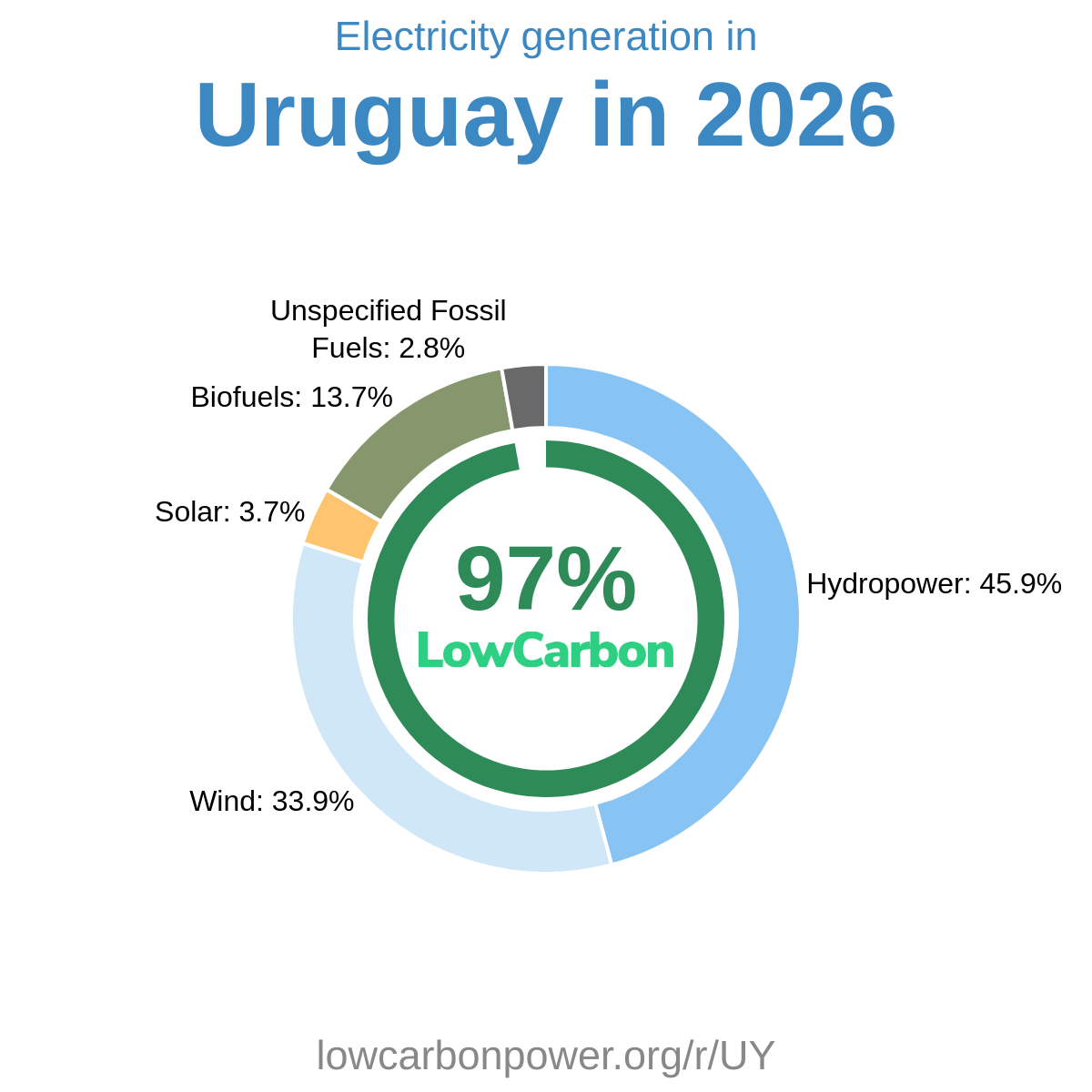
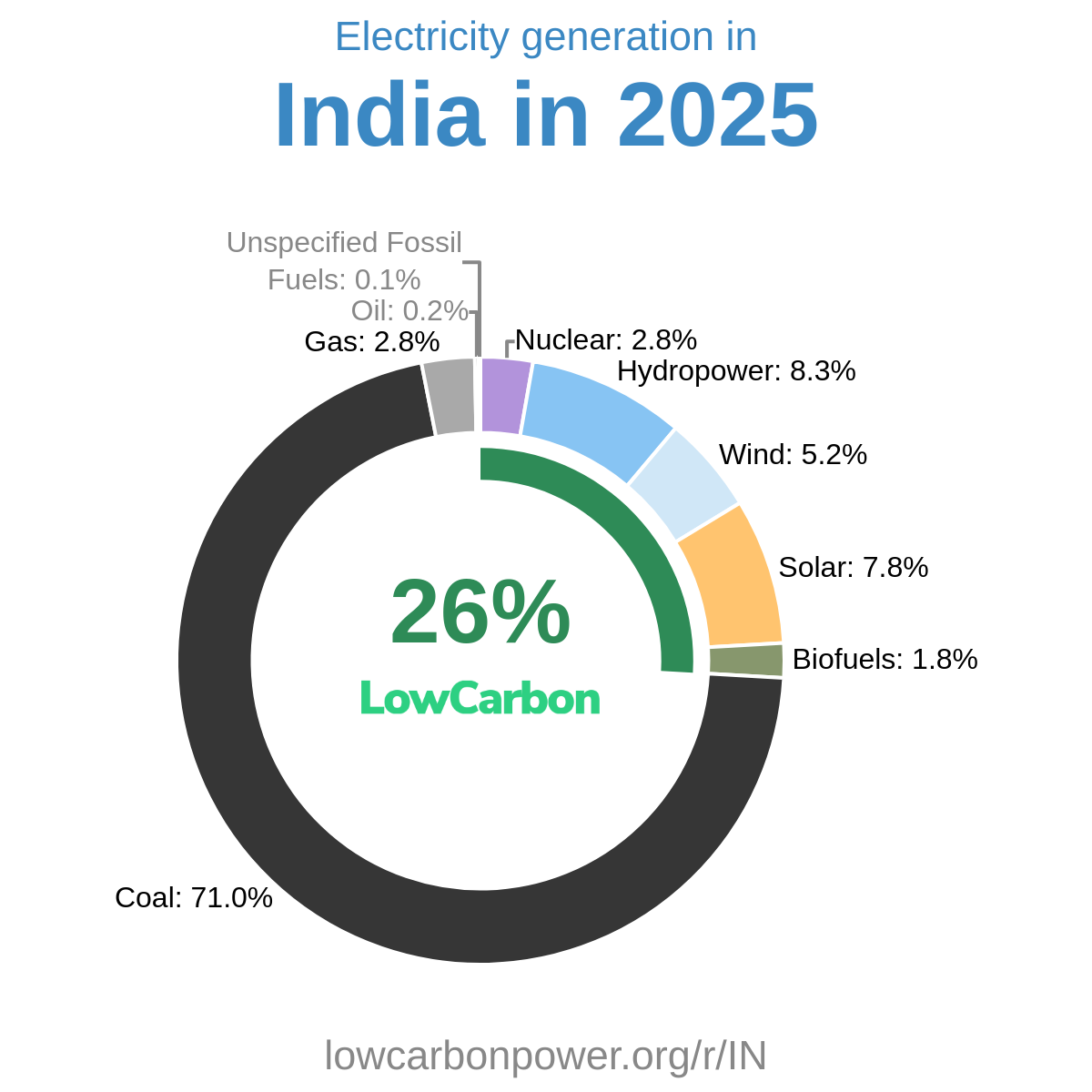
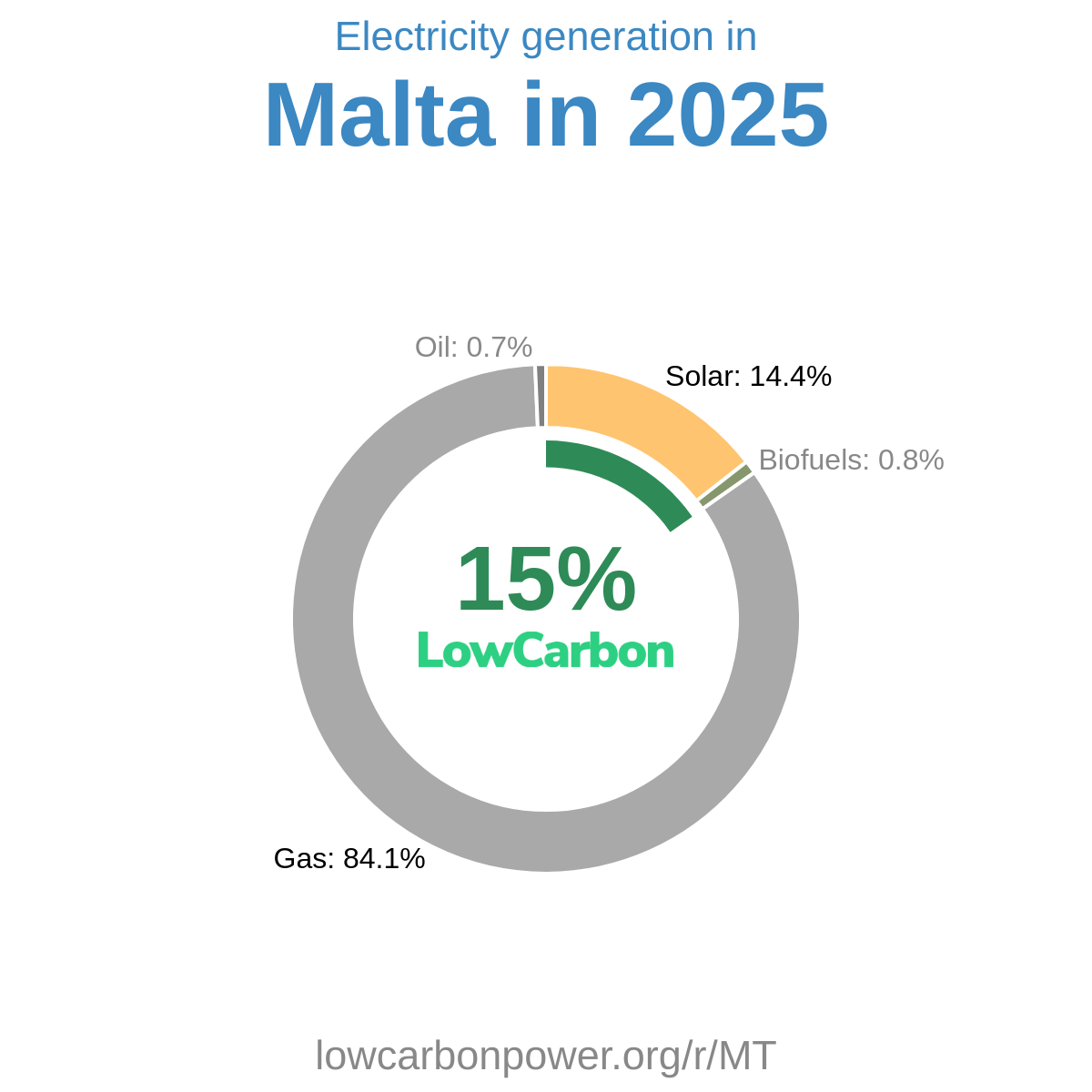
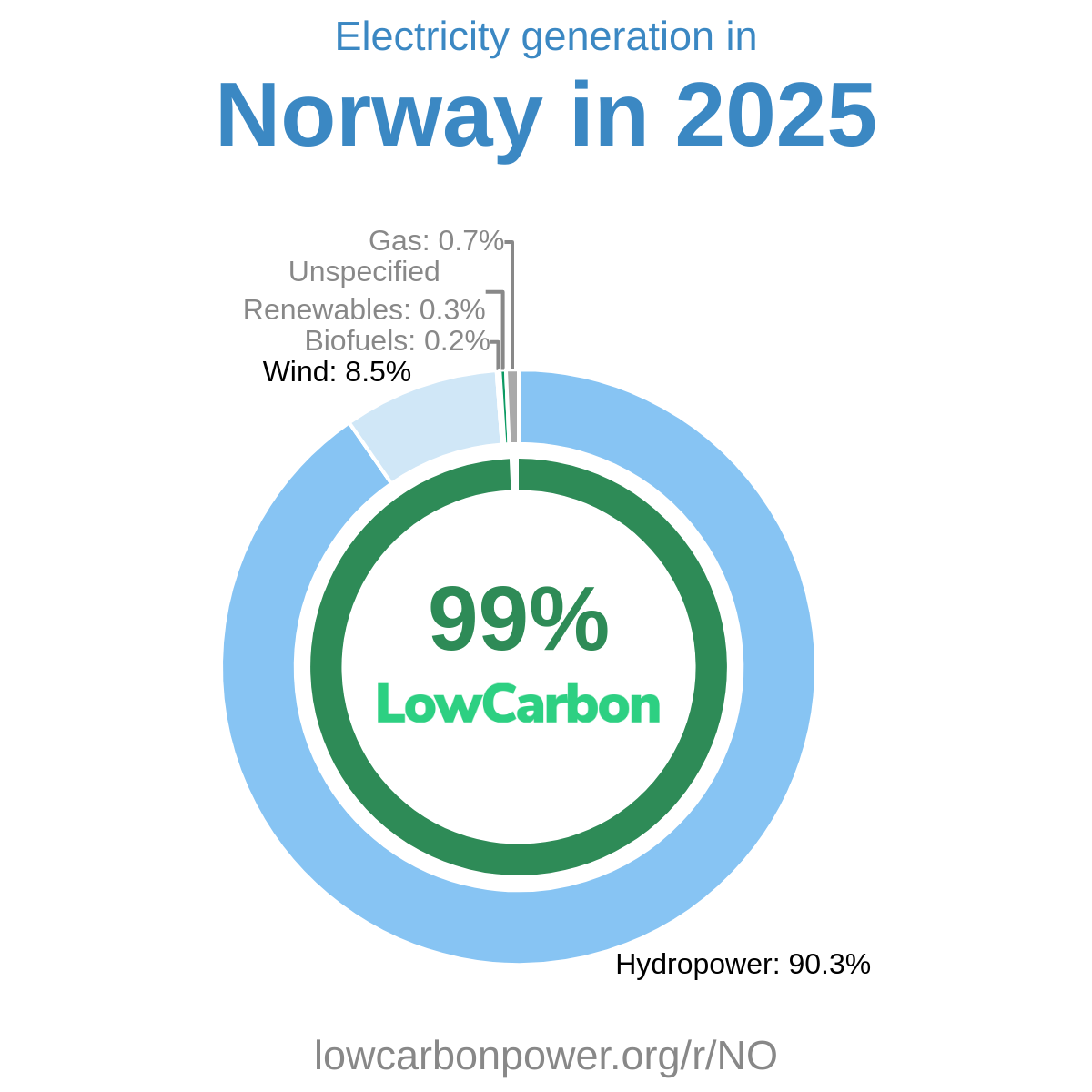
LowCarbonPower.org Methodology
This document explains how the electricity data published on LowCarbonPower.org is produced: where the numbers come from, how we reconcile sources that disagree, and how we turn many separate datasets into a single, consistent picture of how each country and region generates its electricity.
What we are trying to measure
For every country and region, and for as many years (and recent months) as the data allows, we want a complete and internally-consistent breakdown of:
- Electricity generation by source — coal, gas, oil, nuclear, hydro, wind, solar, biofuels, geothermal, and so on.
- Net imports — the electricity a region buys from or sells to its neighbours.
- Total electricity supply — generation plus net imports.
From this breakdown we derive the figures shown across the site: the low-carbon share of electricity, estimated CO₂ emissions, an electrification estimate, and country rankings.
Different providers report electricity in different units, so the first thing we do with every number is convert it to a single common unit: terawatt-hours (TWh).
A single, shared definition of energy types
The central challenge is that every data provider describes fuels differently. One source says "Natural Gas", another "G3000", another "燃氣", another "Generation_NG_natural_gas". One reports a single "Renewables" figure; another breaks it into wind, solar, hydro and biomass.
To make sources comparable, we map every provider's labels onto one shared hierarchy of energy types. At the top is total electricity, which splits into low-carbon and fossil sources (plus other and net imports). Low-carbon splits into nuclear and renewables; renewables split into hydro and non-hydro renewables; non-hydro renewables split into wind, solar, geothermal and biofuels; and solar is further split into utility-scale and behind-the-meter (rooftop) solar. Fossil splits into coal, gas, oil and an "unspecified fossil" residual.
Because every source is translated into this same tree, we can compare them directly, fill gaps in one source with another, and always know how any aggregate (e.g. "fossil") relates to its parts (coal + gas + oil + unspecified). We similarly normalise every country and territory name onto a single ISO standard, so that "Czechia", "Czech Republic" and "Czech Rep." are recognised as the same place, and supranational aggregates such as "OECD" or "EU27" are excluded to avoid double-counting.
Where the data comes from
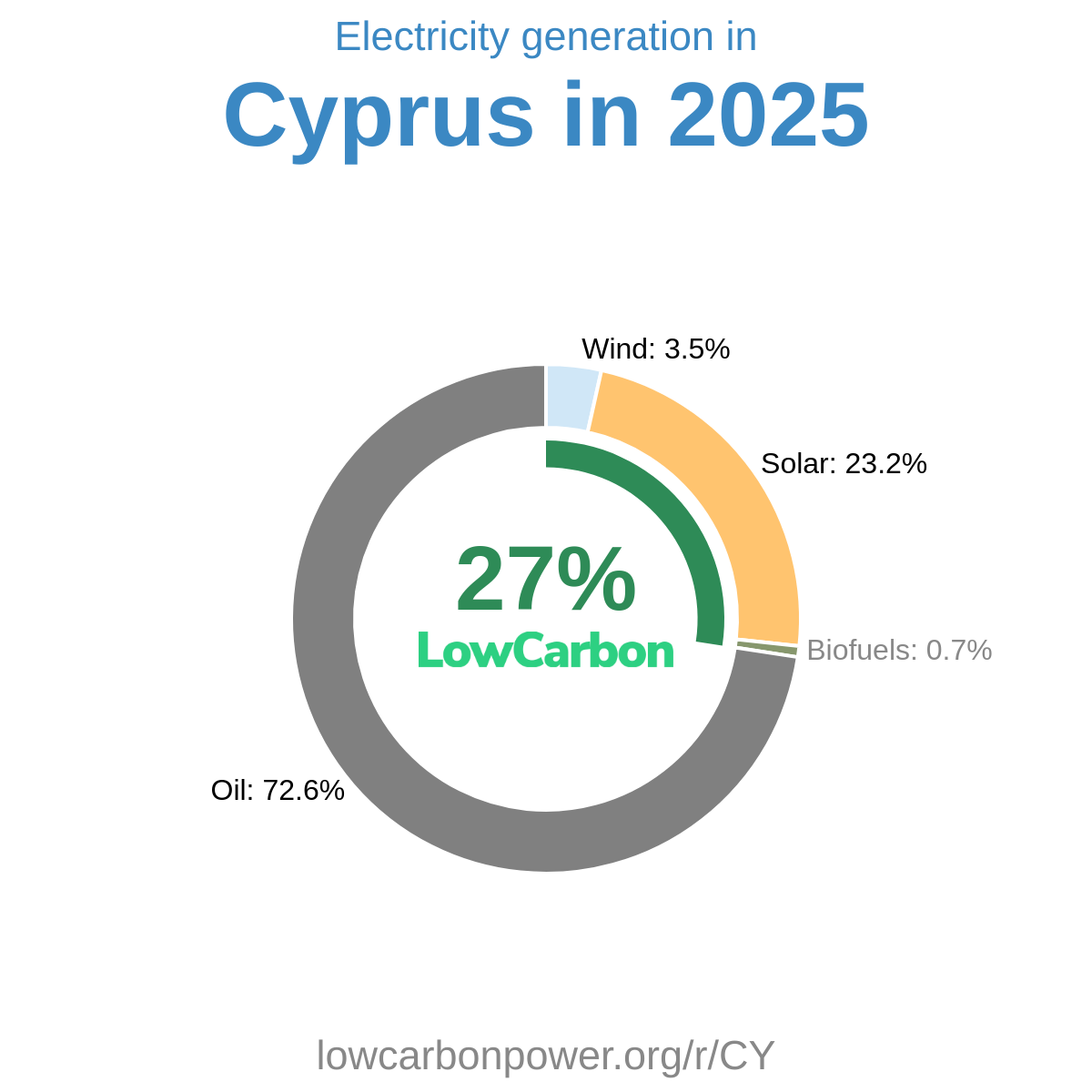
We combine roughly fifteen independent providers, each with different strengths in coverage, timeliness and detail. The most important are:
- International Energy Agency (IEA) — global yearly generation by fuel and primary-energy balances, plus a monthly series covering net production, imports and exports for many countries.
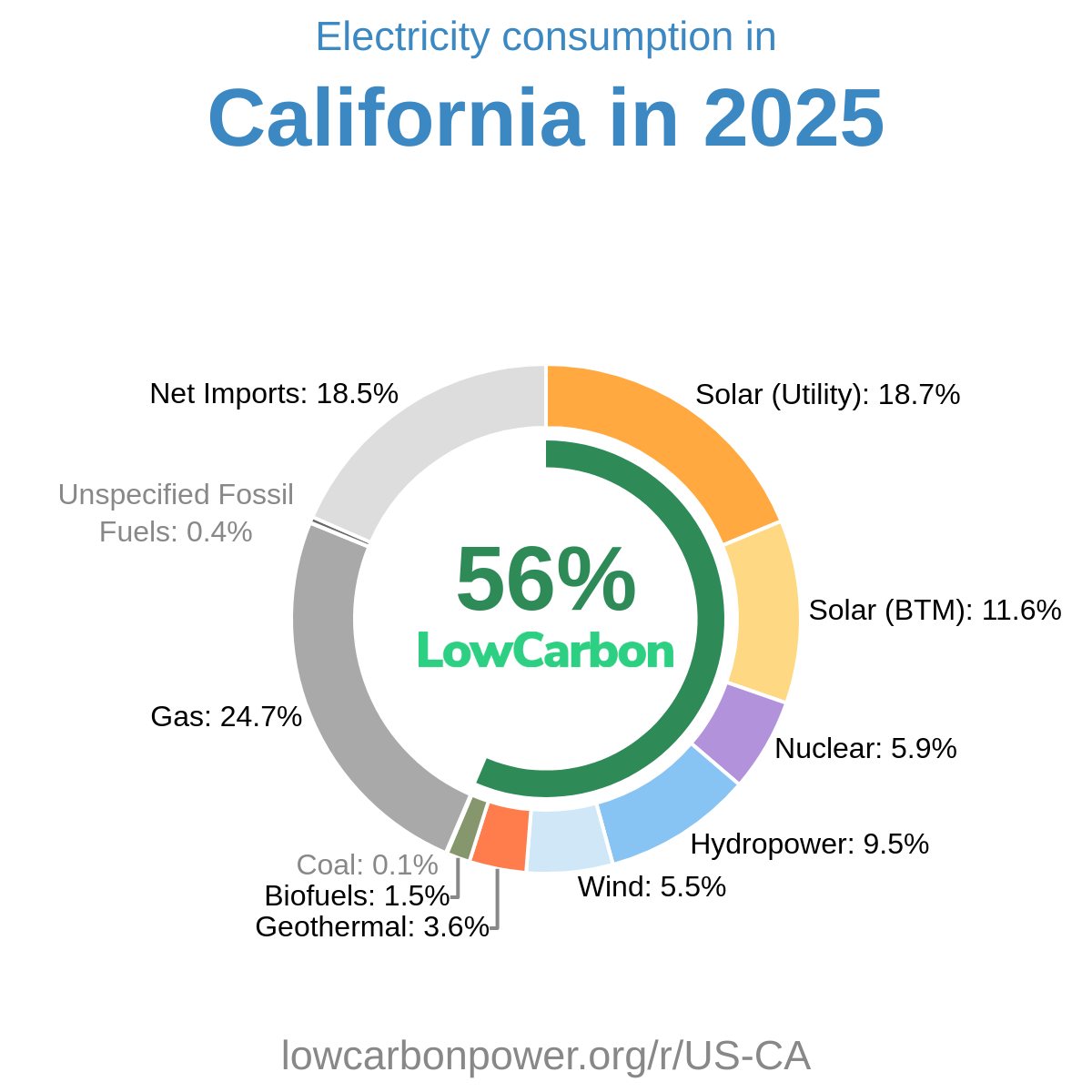
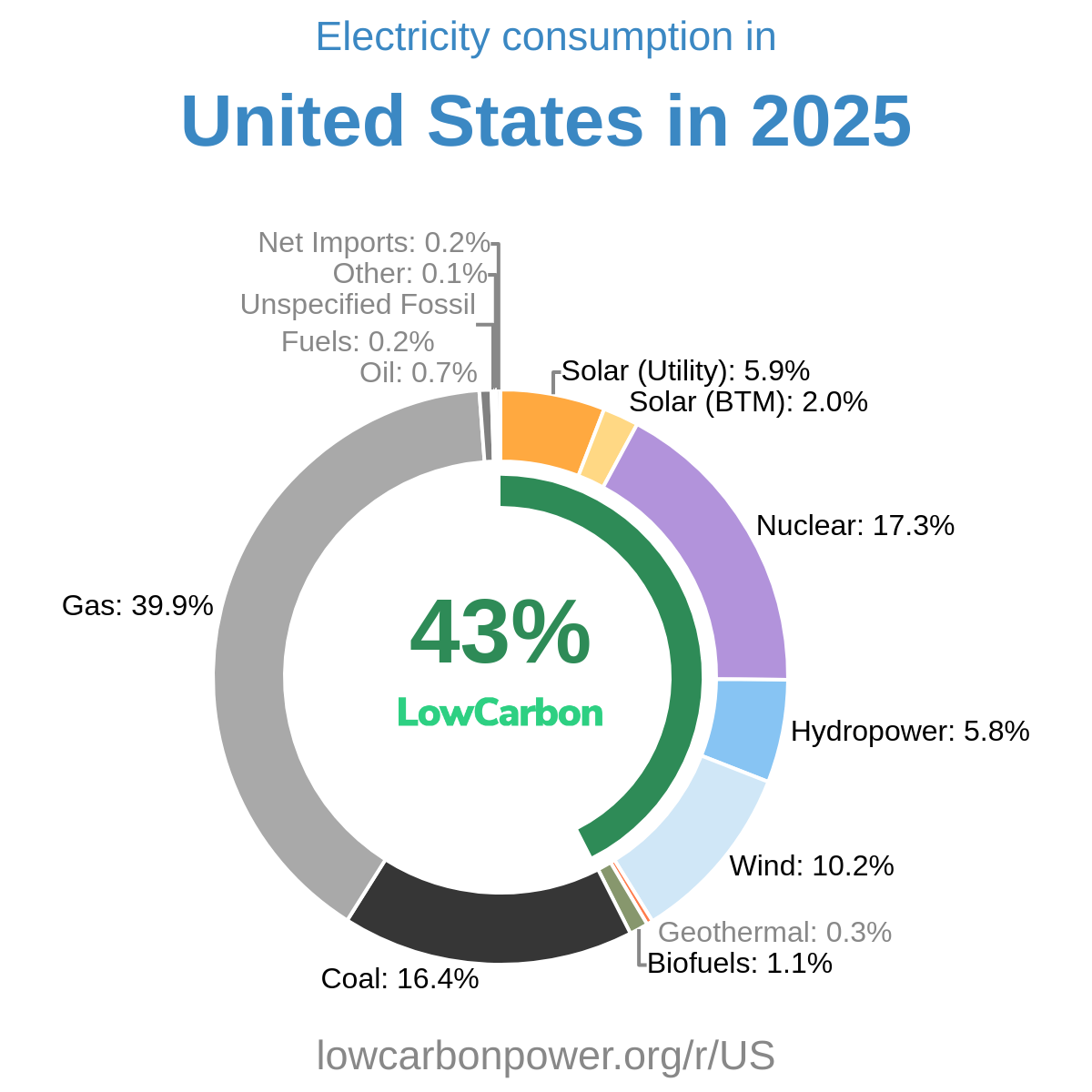
- U.S. Energy Information Administration (EIA) — global and U.S. yearly generation, plus detailed monthly generation for individual U.S. states and grid regions (including data reconstructed from daily and hourly figures).
- Ember — global yearly and monthly electricity generation and net imports.
- Energy Institute Statistical Review (formerly BP) — long-running global yearly generation and primary-energy consumption.
- Eurostat — monthly electricity generation by fuel for European countries.
- ENTSO-E — near-real-time European generation, cross-border flows and demand, aggregated up from sub-hourly measurements.
- World Bank — yearly generation shares, which we convert to absolute figures.
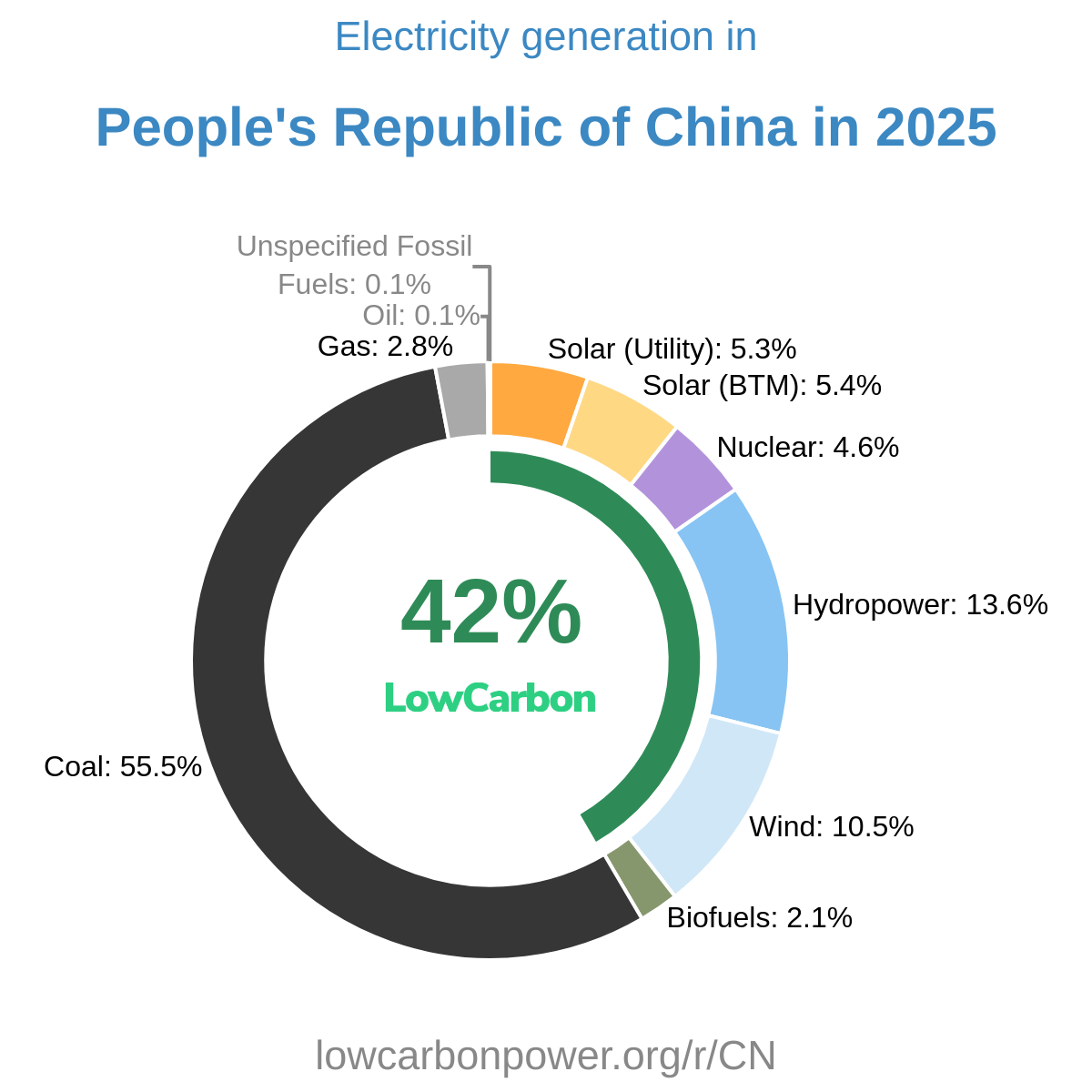
- National statistics for large markets — United States (EIA, as mentioned above), People's Republic of China (National Bureau of Statistics and the National Energy Administration) and Republic of China (Taiwan), where official data is more detailed or more current than the global aggregators.
- Enerdata and IEA — yearly net-imports (trade) figures.
- Sandia National Laboratories — a global database of energy-storage projects.
- Historical reconstructions — long-run world generation back to 1900 used to backfill early years.
Each provider's raw files live in the project's sources directory, alongside the scripts used to download them.
How each source is parsed
Every provider is read into the same shape: for a given fuel and country, a value for each year (or each month, written as YYYY-MM). Several recurring transformations happen at this stage:
- Unit conversion. GWh, kWh, ktoe, petajoules and exajoules are all converted to TWh using the appropriate factors.
- Cumulative-to-periodic conversion. Chinese statistics are published as year-to-date running totals, so we difference consecutive months to recover the value for each individual month and quarter, and reconcile those against the published annual figures, preferring official, non-revised, higher-precision numbers when versions conflict.
- Sub-hourly to monthly aggregation. ENTSO-E publishes generation and cross-border flows at 15-, 30- or 60-minute resolution; we sum these into monthly totals and convert power to energy.
- Monthly-to-yearly roll-ups. When all twelve months of a year are present, we sum them to produce that year's total. The most recent, incomplete period is treated as provisional and generally excluded from yearly totals.
- Gap handling. Early years with missing or unreliable fuel data are trimmed so they don't distort a country's history.
Trusting the data: continuous cross-checking
We do not take any single number at face value. Throughout the process we run two kinds of consistency check:
- Components must sum to their aggregate. Coal + gas + oil + unspecified must equal the reported fossil total; wind + solar + hydro + biofuels + geothermal must equal renewables; and so on, down the whole hierarchy.
- Countries must sum to the world. Where a source reports a global total, it must match the sum of its individual countries.
Each check has a tolerance that encodes what we know about a source's quirks — for example, that a particular provider's biofuels data is missing before 1990, that a given year is known to be incomplete, or that small rounding differences are acceptable. When a discrepancy exceeds tolerance, the process stops and flags the offending figures rather than silently publishing a number we can't explain. This is how data-quality problems get caught before they reach the website.
For the current, still-incomplete year, we relax some of these checks for the fuels most affected by partial-year reporting, so that provisional monthly data isn't rejected just because it doesn't yet add up to a full annual figure.
Combining many sources into one answer
After parsing, we have many overlapping views of the same country-year — for example, the IEA, Ember and Eurostat might all have a figure for Germany in 2022. For each country and each year (or month), we choose one source to use, based on:
- Reliability — a manually-tuned preference order built from experience with each provider (for instance, national statistics and the IEA's yearly data rank highly; near-real-time and forecast sources rank lower).
- Detail — a source that resolves electricity into more specific fuels is preferred over one that only gives broad categories, because it produces a richer breakdown.
We record which source was chosen for every single data point, so the provenance of any figure on the site is fully traceable.
Where the chosen source is missing something another source has — for example, a primary-energy value, or a coal/gas/oil split for a lump reported only as "fossil" — we patch that detail in from the next-best source, using the secondary source's proportions rather than its absolute totals so the numbers stay consistent with the chosen source.
A few special cases are handled here:
- Behind-the-meter (rooftop) solar. Some sources include small-scale rooftop solar in their totals and some don't. We track this explicitly so that utility-scale and rooftop solar can be separated, and so we can publish both "with" and "without" rooftop-solar versions of the data.
- Electrification. Where primary-energy data and a year-by-year thermal-efficiency assumption are available, we estimate what share of a country's total energy use is electricity.
Finally, we rebuild the fuel hierarchy from the chosen figures (re-deriving fossil, low-carbon and other parent totals from their parts), and verify once more that everything adds up.
Net imports (trade)
Net imports are handled separately from generation, because the sign matters (a country can be a net importer or a net exporter) and because providers disagree more about trade than about generation.
We gather every available trade source — yearly figures from Enerdata and the IEA, and monthly figures from ENTSO-E, the IEA, Ember and the EIA — and reconcile them against each other. For each country and period, the sources are compared to their average, and disagreements beyond a tolerance are flagged; less-reliable sources are dropped when better ones are available. The most complete source (Enerdata for yearly figures) is generally preferred.
We then fold the reconciled trade values into the generation dataset: net imports are added to a country's total electricity supply, while net exports are recorded but not subtracted from generation. We produce both an "including net imports" and an "excluding net imports" version of the dataset.
For the most current picture, we also compute a rolling trailing-twelve-month figure for each country from the monthly sources, choosing a consistent twelve-month window so that, for instance, the rooftop-solar treatment doesn't change partway through the window.
Building regions, emissions, rankings and storage
Once each country is finalised, we build the remaining published quantities:
- Region groups. We aggregate countries into groups such as the EU, Sub-Saharan Africa and the world, summing their members and harmonising the range of years each group can cover.
- CO₂ emissions. Each fuel is assigned an emissions factor in grams of CO₂-equivalent per kilowatt-hour (for example, coal ~820, gas ~490, oil ~650, biofuels ~230, solar ~45, hydro ~24, nuclear ~12, wind ~11). Multiplying each fuel's generation by its factor gives an emissions estimate; for aggregate or uncertain fuels we use a range to produce low, central and high estimates.
- Rankings. Countries are ranked by their low-carbon share of electricity, both for the latest year and for every historical year.
- Energy storage. From the storage-project database we estimate installed storage power and energy by country and year, based on when each project was commissioned (and decommissioned).
What gets published
The process produces a small set of combined datasets covering all sources and all regions, offered in both JSON and CSV:
- A main dataset including net imports and a matching one excluding net imports.
- Monthly versions, and versions with and without behind-the-meter solar.
- Per-source datasets, so each provider's view can be inspected on its own, plus merged per-provider views that combine a provider's yearly and monthly data.
- A separate energy-storage dataset.
Each dataset lists the available years and energy types, and for every region gives the generation by fuel over time, the most-specific fuels present in each year, the source chosen for each year, and the derived emissions, electrification, rankings and (where relevant) the member countries of a group.
Data revisions
The figures we publish for a given month are not final when first released. Charts across the site always show the latest data, so a number can change after it first appears — and the charts in an older monthly report may no longer match the prose that was written when that report was published.
Monthly values change for a few reasons:
- Later months reshape earlier ones. For some countries a coarse total (a quarter or a year) is shared out across its months. When a new month arrives, that aggregate is re-apportioned, so the values for earlier months in the same period shift even though no provider corrected them. The year-to-date total usually stays put while the split between months moves.
- The chosen source or basis can change. As more data becomes available we may switch to a more complete or more detailed provider for a region and month, which can move the baseline. Whether a month's total includes behind-the-meter (rooftop) solar can likewise change as that estimate firms up, shifting the comparison.
- Providers revise their own data. Upstream sources routinely restate recent months as audited figures replace provisional ones.
Because of this, where a report's charts draw on data for months after the report's period, we show a notice that the figures may have been revised since publication and link back to this page. The original written commentary is left unchanged as a record of what was known at the time.
In summary
- Download raw electricity data from around fifteen providers.
- Convert everything to a common unit (TWh) and translate every provider's fuel labels and country names onto one shared definition.
- Continuously cross-check that fuels sum to their aggregates and that countries sum to world totals, stopping when something can't be reconciled.
- For each country and period, pick the most reliable and most detailed source that has a complete figure — recording where every number came from — and patch in missing detail from other sources.
- Reconcile net imports separately and fold them into the totals.
- Add behind-the-meter solar handling, emissions, electrification, region groups, rankings and storage.
- Publish combined and per-source datasets in JSON and CSV.